KubernetesドキュメントサイトではHugoというサイトジェネレータを使ったのですが、似たようなツールにMkDocsというものがあり、試してみた。
(そのうちGitHub Pagesに置きたい)
www.mkdocs.org
大まかな流れとしては、Markdown形式でドキュメントを指定のパスに置いて、mkdocs serveするとローカルでサーバー起動して動作確認でき、mkdocs buildするとhtmlファイルやcssなどが生成される、というもの。
テーマとかまだ何も設定してないけど、まずは公式のGetting Startedにそって試してみた。
インストール
pipでインストールする。
(mkdocs) [zaki@cloud-dev mkdocs]$ pip list
Package Version
---------- -------
pip 21.1.2
setuptools 39.2.0
(mkdocs) [zaki@cloud-dev mkdocs]$ ls
venv
(mkdocs) [zaki@cloud-dev mkdocs]$ cat requirements.txt
mkdocs
(mkdocs) [zaki@cloud-dev mkdocs]$
(mkdocs) [zaki@cloud-dev mkdocs]$
(mkdocs) [zaki@cloud-dev mkdocs]$ pip install -r requirements.txt
Collecting mkdocs
Downloading mkdocs-1.1.2-py3-none-any.whl (6.4 MB)
|████████████████████████████████| 6.4 MB 4.6 MB/s
Collecting lunr[languages]==0.5.8
Downloading lunr-0.5.8-py2.py3-none-any.whl (2.3 MB)
|████████████████████████████████| 2.3 MB 11.3 MB/s
Collecting click>=3.3
Downloading click-8.0.1-py3-none-any.whl (97 kB)
|████████████████████████████████| 97 kB 9.4 MB/s
Collecting Markdown>=3.2.1
Downloading Markdown-3.3.4-py3-none-any.whl (97 kB)
|████████████████████████████████| 97 kB 9.8 MB/s
Collecting Jinja2>=2.10.1
Using cached Jinja2-3.0.1-py3-none-any.whl (133 kB)
Collecting livereload>=2.5.1
Downloading livereload-2.6.3.tar.gz (25 kB)
Collecting PyYAML>=3.10
Using cached PyYAML-5.4.1-cp36-cp36m-manylinux1_x86_64.whl (640 kB)
Collecting tornado>=5.0
Downloading tornado-6.1-cp36-cp36m-manylinux2010_x86_64.whl (427 kB)
|████████████████████████████████| 427 kB 10.9 MB/s
Collecting six>=1.11.0
Using cached six-1.16.0-py2.py3-none-any.whl (11 kB)
Collecting future>=0.16.0
Downloading future-0.18.2.tar.gz (829 kB)
|████████████████████████████████| 829 kB 11.2 MB/s
Collecting nltk>=3.2.5
Downloading nltk-3.6.2-py3-none-any.whl (1.5 MB)
|████████████████████████████████| 1.5 MB 11.4 MB/s
Collecting importlib-metadata
Downloading importlib_metadata-4.2.0-py3-none-any.whl (16 kB)
Collecting MarkupSafe>=2.0
Using cached MarkupSafe-2.0.1-cp36-cp36m-manylinux2010_x86_64.whl (30 kB)
Collecting joblib
Downloading joblib-1.0.1-py3-none-any.whl (303 kB)
|████████████████████████████████| 303 kB 10.4 MB/s
Collecting regex
Downloading regex-2021.4.4-cp36-cp36m-manylinux2014_x86_64.whl (722 kB)
|████████████████████████████████| 722 kB 10.5 MB/s
Collecting tqdm
Downloading tqdm-4.61.0-py2.py3-none-any.whl (75 kB)
|████████████████████████████████| 75 kB 8.5 MB/s
Collecting zipp>=0.5
Using cached zipp-3.4.1-py3-none-any.whl (5.2 kB)
Collecting typing-extensions>=3.6.4
Using cached typing_extensions-3.10.0.0-py3-none-any.whl (26 kB)
Using legacy 'setup.py install' for future, since package 'wheel' is not installed.
Using legacy 'setup.py install' for livereload, since package 'wheel' is not installed.
Installing collected packages: zipp, typing-extensions, importlib-metadata, tqdm, six, regex, joblib, future, click, tornado, nltk, MarkupSafe, lunr, PyYAML, Markdown, livereload, Jinja2, mkdocs
Running setup.py install for future ... done
Running setup.py install for livereload ... done
Successfully installed Jinja2-3.0.1 Markdown-3.3.4 MarkupSafe-2.0.1 PyYAML-5.4.1 click-8.0.1 future-0.18.2 importlib-metadata-4.2.0 joblib-1.0.1 livereload-2.6.3 lunr-0.5.8 mkdocs-1.1.2 nltk-3.6.2 regex-2021.4.4 six-1.16.0 tornado-6.1 tqdm-4.61.0 typing-extensions-3.10.0.0 zipp-3.4.1
(mkdocs) [zaki@cloud-dev mkdocs]$
お試し
プロジェクト作成
my-projectプロジェクトを作成
(mkdocs) [zaki@cloud-dev mkdocs]$ mkdocs new my-project
INFO - Creating project directory: my-project
INFO - Writing config file: my-project/mkdocs.yml
INFO - Writing initial docs: my-project/docs/index.md
(mkdocs) [zaki@cloud-dev mkdocs]$ ls
my-project requirements.txt venv
(mkdocs) [zaki@cloud-dev mkdocs]$ cd my-project/
(mkdocs) [zaki@cloud-dev my-project]$ ls
docs mkdocs.yml
動作確認用サーバー起動
(mkdocs) [zaki@cloud-dev my-project]$ mkdocs serve
INFO - Building documentation...
INFO - Cleaning site directory
INFO - Documentation built in 0.05 seconds
[I 210527 09:11:55 server:335] Serving on http://127.0.0.1:8000
INFO - Serving on http://127.0.0.1:8000
[Errno 98] Address already in use
8000/TCPとか他で使ってるわ。。
(mkdocs) [zaki@cloud-dev my-project]$ mkdocs serve --help
Usage: mkdocs serve [OPTIONS]
Run the builtin development server
Options:
-a, --dev-addr <IP:PORT> IP address and port to serve documentation
locally (default: localhost:8000)
--livereload Enable the live reloading in the development
server (this is the default)
--no-livereload Disable the live reloading in the
development server.
--dirtyreload Enable the live reloading in the development
server, but only re-build files that have
changed
-f, --config-file FILENAME Provide a specific MkDocs config
-s, --strict Enable strict mode. This will cause MkDocs
to abort the build on any warnings.
-t, --theme [mkdocs|readthedocs]
The theme to use when building your
documentation.
--use-directory-urls / --no-directory-urls
Use directory URLs when building pages (the
default).
-q, --quiet Silence warnings
-v, --verbose Enable verbose output
-h, --help Show this message and exit.
helpを見るとポート単体はなさそうだけど、-aでlistenするアドレスとポート指定できるみたい。
ついでなのでリモートからも接続できるように0.0.0.0で起動。
(firewalld空けないといけないので結局これ使わずにsshのポートフォワードしたけど…)
警告も出てるけど、0.0.0.0はアクセス範囲広くていろいろ注意必要なので、ポートフォワードするなら127.0.0.1:8081で問題ない。
(mkdocs) [zaki@cloud-dev my-project]$ mkdocs serve -a 0.0.0.0:8081
INFO - Building documentation...
WARNING - Config value: 'dev_addr'. Warning: The use of the IP address '0.0.0.0' suggests a production environment or the use of a proxy to connect to the MkDocs server. However, the MkDocs' server is intended for local development purposes only. Please use a third party production-ready server instead.
INFO - Cleaning site directory
INFO - Documentation built in 0.05 seconds
[I 210527 09:13:51 server:335] Serving on http://0.0.0.0:8081
INFO - Serving on http://0.0.0.0:8081
[I 210527 09:13:51 handlers:62] Start watching changes
INFO - Start watching changes
[I 210527 09:13:51 handlers:64] Start detecting changes
INFO - Start detecting changes
実行するとこの通り、フォアグラウンドで動作し、docs以下のMarkdownファイルを元にwebアクセス経由でページ表示できるようになる。
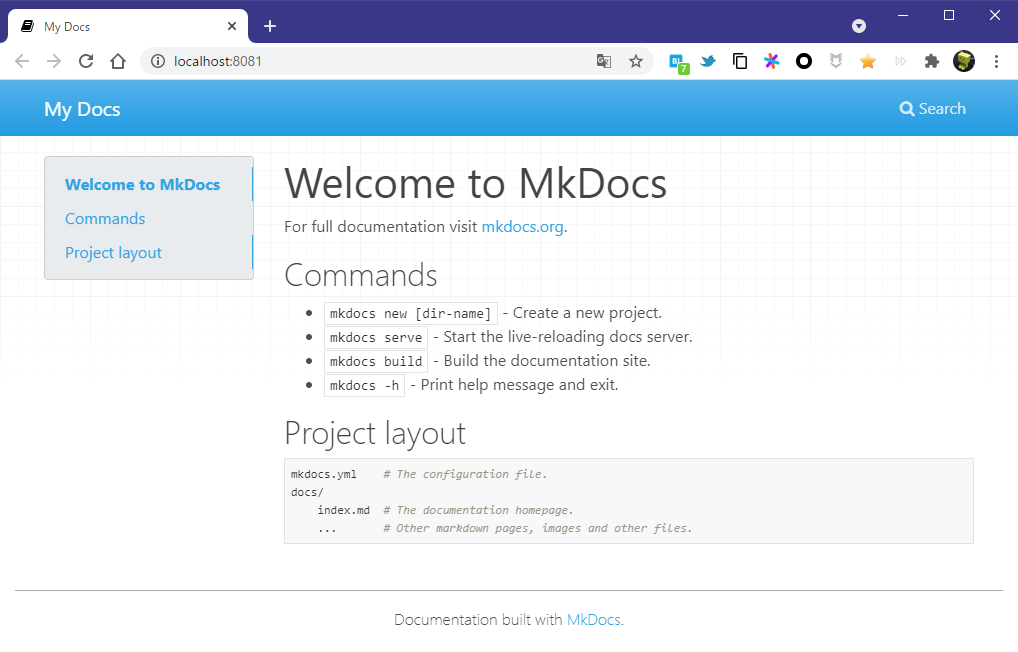
プロジェクト作成時に自動で生成されるインデックスページは以下の通り。
# Welcome to MkDocs
For full documentation visit [mkdocs.org](https://www.mkdocs.org).
## Commands
* `mkdocs new [dir-name]` - Create a new project.
* `mkdocs serve` - Start the live-reloading docs server.
* `mkdocs build` - Build the documentation site.
* `mkdocs -h` - Print help message and exit.
## Project layout
mkdocs.yml # The configuration file.
docs/
index.md # The documentation homepage.
... # Other markdown pages, images and other files.
このままサーバー起動しブラウザでアクセスすると以下のように表示される。
ページ追加
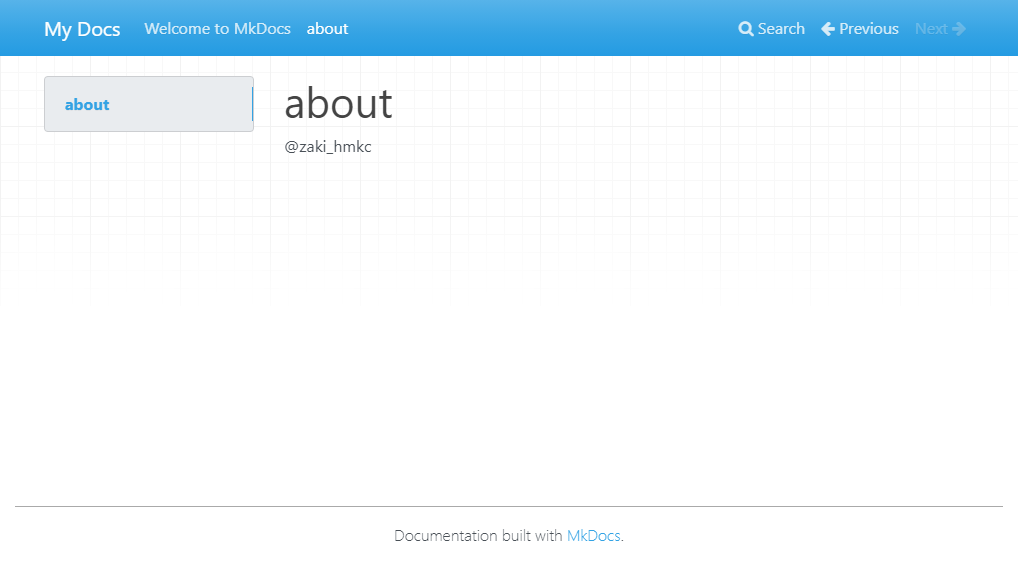
docs/about.mdを追加してみる。
内容は以下の通り。
# about
@zaki_hmkc
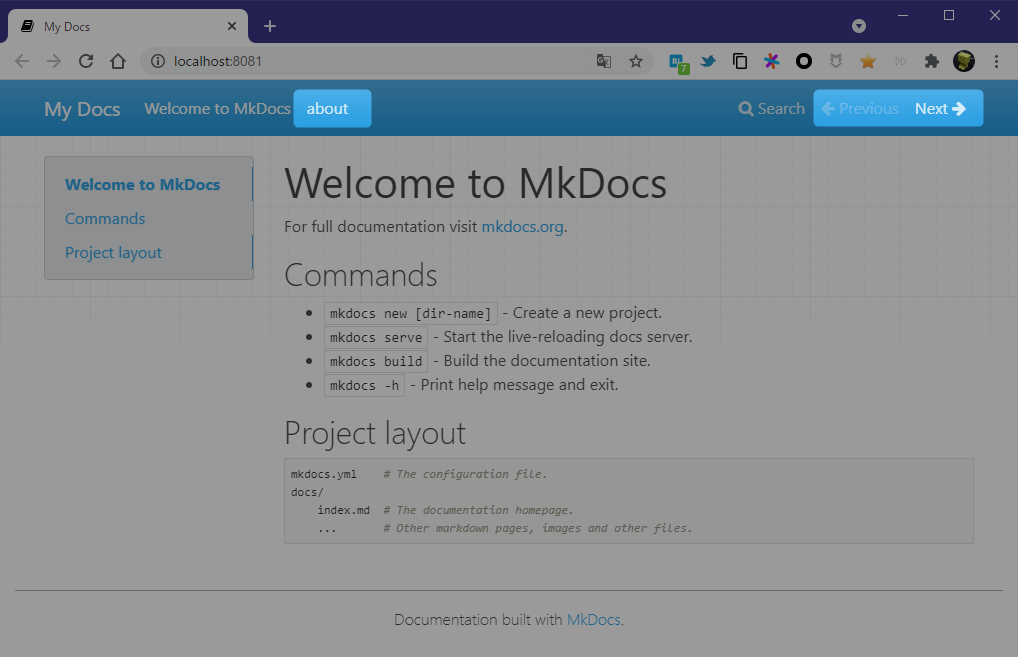
サーバーは起動したままにしておくと、ファイルの変更を自動で検知し動的にページ更新してくれる。
[I 210527 09:18:27 watcher:111] Running task: builder (delay: None)
INFO - Running task: builder (delay: None)
INFO - Building documentation...
WARNING - Config value: 'dev_addr'. Warning: The use of the IP address '0.0.0.0' suggests a production environment or the use of a proxy to connect to the MkDocs server. However, the MkDocs' server is intended for local development purposes only. Please use a third party production-ready server instead.
[I 210527 09:18:27 handlers:95] Reload 1 waiters: /home/zaki/local/mkdocs/my-project/docs/about.md
INFO - Reload 1 waiters: /home/zaki/local/mkdocs/my-project/docs/about.md
[I 210527 09:18:28 handlers:135] Browser Connected: http://localhost:8081/
INFO - Browser Connected: http://localhost:8081/
[I 210527 09:18:59 watcher:111] Running task: builder (delay: None)
INFO - Running task: builder (delay: None)
INFO - Building documentation...
WARNING - Config value: 'dev_addr'. Warning: The use of the IP address '0.0.0.0' suggests a production environment or the use of a proxy to connect to the MkDocs server. However, the MkDocs' server is intended for local development purposes only. Please use a third party production-ready server instead.
[I 210527 09:18:59 handlers:95] Reload 1 waiters: /home/zaki/local/mkdocs/my-project/docs/about.md
INFO - Reload 1 waiters: /home/zaki/local/mkdocs/my-project/docs/about.md
[I 210527 09:18:59 handlers:135] Browser Connected: http://localhost:8081/
INFO - Browser Connected: http://localhost:8081/
[I 210527 09:19:06 handlers:135] Browser Connected: http://localhost:8081/
INFO - Browser Connected: http://localhost:8081/
生成されたページはこの通り。
サイト名の変更
ページ名はテンプレート生成したときの初期値はMy Docsになっているが、ルートのmkdocs.ymlで指定可能。
site_name: mkdocsお試し
この内容に変更すると、表示は以下の通り。
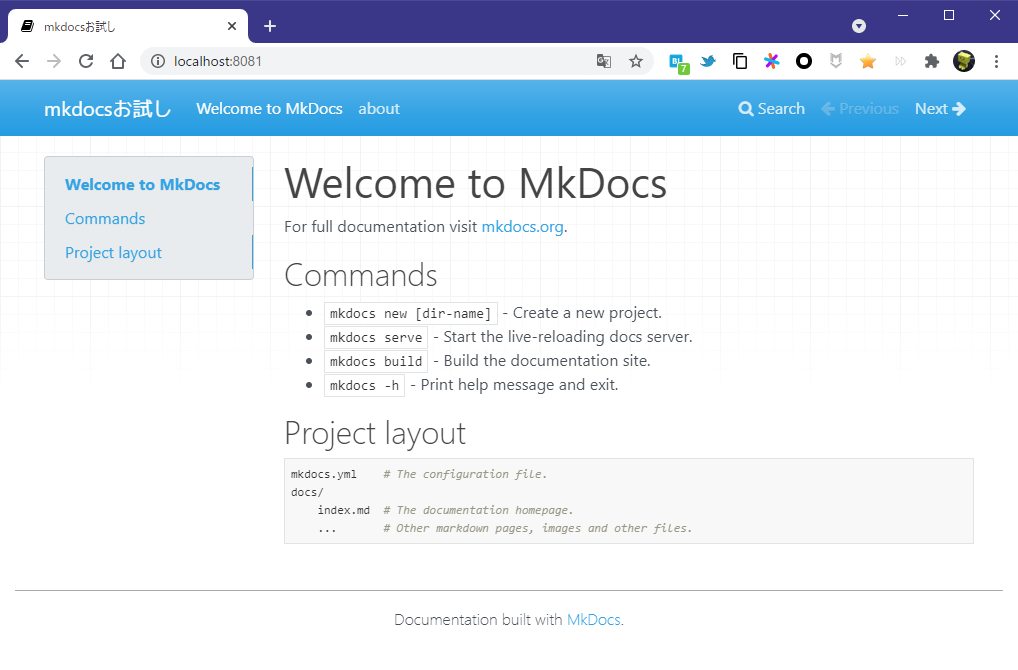
サイトのビルド
(mkdocs) [zaki@cloud-dev my-project]$ ls
docs mkdocs.yml
(mkdocs) [zaki@cloud-dev my-project]$ mkdocs build
INFO - Cleaning site directory
INFO - Building documentation to directory: /home/zaki/local/mkdocs/my-project/site
INFO - Documentation built in 0.05 seconds
(mkdocs) [zaki@cloud-dev my-project]$ ls
docs mkdocs.yml site
mkdocs buildを実行すると、(デフォルトでは)siteディレクトリ以下にMarkdownを元にwebページ用のhtml他のファイルが作成される。
(mkdocs) [zaki@cloud-dev my-project]$ ls -F site/
404.html about/ css/ fonts/ img/ index.html js/ search/ sitemap.xml sitemap.xml.gz
このファイルをwebサーバーに置けば、動作確認じに表示されたコンテンツにアクセスできる。
暫定なので(firewalldの設定変更なので)Dockerのhttpdで…
(mkdocs) [zaki@cloud-dev my-project]$ docker run --rm -p 8089:80 -v $PWD/site:/usr/local/apache2/htdocs -d httpd
e03d10f5a697f8e830a6d3c1403ce45f4e3e231539852f0c20a5f82dca878aaf
リモートからwebサーバーにアクセスするとこの通り。
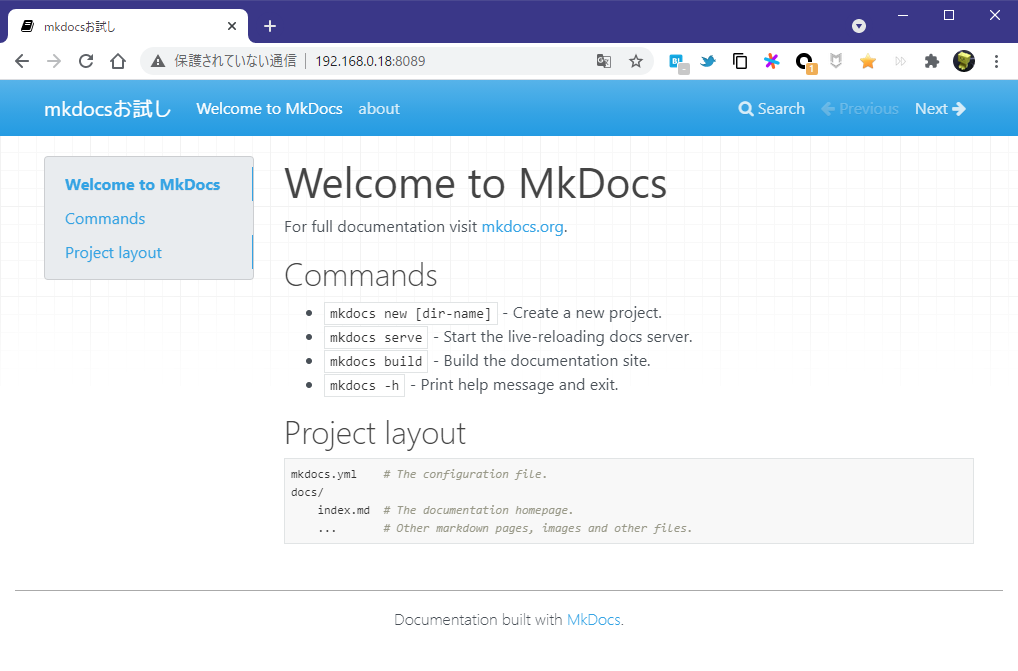
環境
本編と関係ないけど「このディレクトリのファイルをwebサーバー経由でアクセスしたい」はDocker使うと本当に楽だなぁ