オンプレ環境だと必ずと言っていいほど存在する「エクセルのIPアドレス管理台帳」、なんやかやで私も自宅の環境でもスプレッドシート(Excelではない笑)に記入しつつ運用してました。
で、業務で最近NetBoxというアドレス管理などを行うIPAMツールを使うことが増えたので、勉強がてら自宅にも導入してみました。
- NetBoxって何
- インストール
- ログイン
- 管理方針 (仮)
- Devices
- Virtual Machines
- IPアドレス作成 (IP Addressesから)
- IPアドレス使用状況
- APIなど (リンク)
NetBoxって何
めちゃくちゃ雑に言うと「IPアドレス管理台帳のwebアプリ版」と解釈してます。
詳しくは公式サイトと、IPAM・DCIMなどで検索すると詳しい情報が見つかると思います。
元々はDigitalOcean社のネットワークエンジニアリングチームが開発したもので、PythonのDjangoで実装されています。
インストール
環境
以下の環境にデプロイ。
[zaki@manager ~]$ cat /etc/centos-release CentOS Linux release 7.9.2009 (Core) [zaki@manager ~]$ docker -v Docker version 20.10.2, build 2291f61 [zaki@manager ~]$ docker-compose -v docker-compose version 1.27.4, build 40524192
また、NetBoxのバージョンは v2.10.3 となっている。
NetBoxインストール
Dockerのコンテナイメージが公開されており、Quickstartに沿ってDocker Composeを使えばサクッとデプロイできる。動作も軽量。
[zaki@manager local]$ git clone -b release https://github.com/netbox-community/netbox-docker.git Cloning into 'netbox-docker'... remote: Enumerating objects: 5, done. remote: Counting objects: 100% (5/5), done. remote: Compressing objects: 100% (5/5), done. remote: Total 2417 (delta 0), reused 0 (delta 0), pack-reused 2412 Receiving objects: 100% (2417/2417), 624.70 KiB | 588.00 KiB/s, done. Resolving deltas: 100% (1371/1371), done. [zaki@manager local]$ cd netbox-docker/
ここで、ドキュメントだと「ホストOSでは8000/TCPでListenする設定」になるが、8000は別に使ってるので28080/TCPに変更。(数に深い意味はない)
$ tee docker-compose.override.yml <<EOF
version: '3.4'
services:
nginx:
ports:
- 28080:8080
EOF
イメージをpull
[zaki@manager netbox-docker]$ docker-compose pull Pulling redis ... done Pulling postgres ... done Pulling netbox-worker ... done Pulling redis-cache ... done Pulling netbox ... done Pulling nginx ... done
デプロイ
[zaki@manager netbox-docker]$ docker-compose up -d Creating network "netbox-docker_default" with the default driver Creating volume "netbox-docker_netbox-static-files" with local driver Creating volume "netbox-docker_netbox-nginx-config" with local driver Creating volume "netbox-docker_netbox-media-files" with local driver Creating volume "netbox-docker_netbox-postgres-data" with local driver Creating volume "netbox-docker_netbox-redis-data" with local driver Creating netbox-docker_redis-cache_1 ... done Creating netbox-docker_redis_1 ... done Creating netbox-docker_postgres_1 ... done Creating netbox-docker_netbox-worker_1 ... done Creating netbox-docker_netbox_1 ... done Creating netbox-docker_nginx_1 ... done
[zaki@manager netbox-docker]$ docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------------------
netbox-docker_netbox-worker_1 python3 /opt/netbox/netbox ... Up
netbox-docker_netbox_1 /opt/netbox/docker-entrypo ... Up
netbox-docker_nginx_1 /docker-entrypoint.sh ngin ... Up 80/tcp, 0.0.0.0:28080->8080/tcp,0.0.0.0:49153->8080/tcp
netbox-docker_postgres_1 docker-entrypoint.sh postgres Up 5432/tcp
netbox-docker_redis-cache_1 docker-entrypoint.sh sh -c ... Up 6379/tcp
netbox-docker_redis_1 docker-entrypoint.sh sh -c ... Up 6379/tcp
割とすぐUpにはなるが、初回は内部ではDBの初期データ構築が行われている。
[zaki@manager netbox-docker]$ docker-compose logs -f Attaching to netbox-docker_nginx_1, netbox-docker_netbox_1, netbox-docker_netbox-worker_1, netbox-docker_redis_1, netbox-docker_postgres_1, netbox-docker_redis-cache_1 netbox_1 | 🧬 loaded config '/etc/netbox/config/configuration.py' netbox_1 | 🧬 loaded config '/etc/netbox/config/configuration.py' netbox_1 | 🧬 loaded config '/etc/netbox/config/extra.py' netbox_1 | Operations to perform: netbox_1 | Apply all migrations: admin, auth, circuits, contenttypes, dcim, extras, ipam, secrets, sessions, taggit, tenancy, users, virtualization netbox_1 | Running migrations: : :
ログにnetboxのコンテナでListeneing at ... と出ていればだいたい大丈夫。
netbox_1 | 🧬 loaded config '/etc/netbox/config/configuration.py' netbox_1 | 🧬 loaded config '/etc/netbox/config/configuration.py' netbox_1 | 🧬 loaded config '/etc/netbox/config/extra.py' netbox_1 | netbox_1 | 961 static files copied to '/opt/netbox/netbox/static'. netbox_1 | ✅ Initialisation is done. netbox_1 | [2021-01-09 09:04:31 +0000] [1] [INFO] Starting gunicorn 20.0.4 netbox_1 | [2021-01-09 09:04:31 +0000] [1] [INFO] Listening at: http://0.0.0.0:8001 (1) netbox_1 | [2021-01-09 09:04:31 +0000] [1] [INFO] Using worker: sync netbox_1 | [2021-01-09 09:04:31 +0000] [20] [INFO] Booting worker with pid: 20 netbox_1 | [2021-01-09 09:04:31 +0000] [21] [INFO] Booting worker with pid: 21 netbox_1 | [2021-01-09 09:04:31 +0000] [22] [INFO] Booting worker with pid: 22
webブラウザでHTTPアクセスすればNetBoxの画面にアクセスできる。
コンテナは以下のものが動いているが、起動してしまえば(初回の初期処理が終われば)負荷はあまりない。
- Nginx
- NetBox
- NetBox Worker
- Redis
- PostgreSQL
- Redis Cache
ログイン
画面右上の「Log in」から。
Docker Composeで構築した場合はユーザー名・パスワードともにadminとなっている。
管理方針 (仮)
軽くさわってみた感じだと、自宅の環境(NW機器が特に無く、Linux/Windows等のサーバー・クライアントPCばかり)の管理としてはNUCなどの物理機器の情報はDCIM -> Devicesに、VMはVirtualization -> Virtual Machinesにホスト情報を登録すると良さそうだった。
(あくまで使い方の一つで、私はこうやって使ってみようというもの。使ってるともっと別の使い方が良いと思えば変更するかも。)
ただし、ホスト情報の登録には選択式のパラメタがいくつか必須で、そのパラメタの選択肢を予め作成しておく必要がある。
Devices
デバイス情報を登録するには、以下の必須項目があるので、まずこれらを作成しておく。
- Site
- Device Role
- Device Type
- Manufactures (Device Typeの作成に必要)
あと、必須ではないが、Rackなんかは自宅ラック勢には設定すると楽しいかもしれない。
自宅ラック勢でなくても、マシンの棚があってサーバー・ルーター・モデム・外付けHDDなどの機器がそれぞれ何段目にあるかを登録したりもできるかも?(未確認)
あとTag設定も可能で、これは事前に使いたいタグ情報を作成しておけば、複数のタグを設定できる。
Sites

[Organization -> Sites]から。
画面上部のメニューの+か、Sites画面の右上の+ Addから項目を作成する。
名前の通り場所を登録する。例えば「自宅」とか。
Slugには、URLにも使われるユニークな識別子を入力する。
APIなどでも使用するので、英数字とハイフン程度にしておくのが無難。(たぶん)
名称にスペースを含むとハイフンになるなど、ASCII文字であれば自動で反映される。
| 項目 | 値 |
|---|---|
| Site / Name | 自宅 |
| Site / Slug | home |
| Site / Status | Active |
こんな感じ。

Device Roles
名前の通り、デバイス(今回はホスト)の役割を定義。
サイトと同じ要領で、「Devices」の「Device Roles」から、「+ Add」押下で作成画面になる。
本来はNW機器の役割の登録に使用するっぽいが、自宅の環境はISPのルーターと家電店で買ってきたスイッチくらいしかなく、メインの管理対象はサーバーとクライアントPCのため、あまり細かく分けずに「サーバー」「クライアント」「k8sノード」「ネットワーク」「テンポラリ」みたいに設定してみる。
なお、デバイスに割り当てられるロールは一つのみ。

VM Roleのチェックについては、DevicesだけでなくVirtual MachinesのRoleの設定で割り当て対象とするかどうか、というもの。
(DevicesではRoleの設定は必須だが、Virtual MachinesではRoleの設定は任意)
Manufacturers
Devicesでデバイス登録するのに必須なのはDevice Typesだが、Device Typesの項目を作るのに必須なのがManufacturersになっている。
デバイス登録時にDevice Typesを選択すると、自動的にManufacturersが決定されるようになるため、親子関係に当たる。
なので、初めはmanufacturesにbare metal,VMを設定してDevice TypesにLInux / Windows / ...なんて設定してみたけど構造的にイケてなかったのとVM登録用のVirtual Machinesという項目もあったので、結局名前の通り「Manufacturersには物理デバイス・PCのメーカー」と「Device Typesにはデバイス・PCのモデル名」という使い方にしてみた。

Device Types
Manufacturersに機器メーカーを登録したら、Device Typesに機器のモデル名を登録。
元々データセンターのラックマウントを想定した設定内容のためHeight (U)という項目はあるが、一般のご家庭なので使用しないが必須項目のが目デフォルトの1で。

Deviceの登録
- Site
- Device Role
- Device Type
以上の必須項目の準備ができたのでデバイスを登録する。
名前はホスト名。
前述の通り、Manufacturerは空欄のままでも、「Create」したときに選択していたDevice typeから自動で設定される。
Virtualizationのところで選択できるCluster GroupあるいはClusterは、Virtual Machinesでは必須の項目だが、Devicesでは任意。

画面の通り、一覧ではTypeのフィールドが「Manufacturer + Device Type」という表示になっている。
インタフェースとIPアドレス設定 (デバイスから作成)
Deviceの登録をしただけだと、IPアドレスの設定箇所はない。
IPアドレスを設定するには、対象デバイスの管理画面の+ Add ComponentsからInterfacesでIPアドレスを設定するインタフェースを追加する必要があるので、まずインタフェースを作成する。

インタフェースの作成はインタフェース名とTypeを選ぶ。今どきの物理PCなら1000BASE-Tとかそんな感じのはず。

インタフェースが作成できたら、IPアドレスを設定できる。
IPアドレスは予めIPAM -> IP Addressesで作成性済みのものを割り当てもできるが、インタフェースの画面から新規に作成することもできる。

| 項目 | 値 |
|---|---|
| Address | そのインタフェースのIPアドレス/マスク値 |
| Status | 使ってるのでActive |
| Interface Assignment | 今はデバイスの設定なのでDeviceでホスト名とインタフェース名を指定 |
| primary IP for the device/VM | メインのNICであればチェック |
一覧で表示されるのはPrimary IPのため、primary IP for the device/VMのチェックが入ってないアドレスはデバイス一覧では確認できない。

ちなみに重複したIPアドレスは登録は可能だが、IPAMの画面から見るとDuplicate IP Addressという表示になる。

Virtual Machines
デバイスの登録ができたので、今度はVMを登録してみる。
VMの登録に必要な必須パラメタは以下の通りで、デバイスに比べると項目は少ない。
- Cluster
- Cluster Type (Clusterの作成に必要)
ただし、Clusterの作成にはCluster Typeを作成しておく必要がある。
Cluster Types
Cluster TypeにはVMのプラットフォームの名称を入れておくとよさげ。
ドキュメントではVMware vSphereなど。
うちはvSphereは使ってないのでESXiとかHyper-Vとかのハイパーバイザーを登録しておいてみる。

Cluster TypesはClusterの親情報となり、デバイスにおけるManufacturersとDevice Typesの関係に近い。
Clusters
VMの論理グループを作成できる。
名称とCluster Typeを選択するだけだが、デバイス情報に登録する際に必須だったSite情報もここに設定できる。

自分の環境だとイマイチ使い道が(今のところ)ないので、(とりあえず)ESXiなどのポートグループ名などVMが所属するネットワークを入れておく。
1/28追記: スペースを含んでいてもNetBox上には登録できるが、NetBoxにAPIアクセスするツール側で処理できない場合があるので、アンダーバーを使うなどした方が無難。
(教訓) NetBoxのフィルタ用(属性)各キーにスペースを含めるのはやめよう pic.twitter.com/h4YmcHIvHu
— z a k i (@zaki_hmkc) 2021年1月27日
VMの登録
必須項目であるClusterの準備ができたのでVMを登録する。
前述の通り、デバイスの登録時に使用したRoleも任意で指定できる。

あとオプションだが、VMのリソース(CPUやメモリ、ストレージ)も設定できる。
(ただしストレージは一つのみなので、「ディスク2本載せている」みたいなのは現状では表現できなさそう)

ちなみにこのmanagerはNetBoxを動かしてるホスト。
インタフェースとIPアドレス設定 (VMから作成)
VMを登録しただけだとまだIPアドレスは未設定・設定できないので、デバイスと同様に+ Add Interfacesからインタフェースを追加して、IPアドレスを設定する。

インタフェースを追加したら、デバイスのときと同様に+ボタン押下で新しくIPアドレスを作成・設定できる。
Interface Assignmentについてはデバイスのとき異なり、Virtual Machineタブの方を設定する。

これでVirtual Machinesの画面に戻ると、作成したVMの一覧が表示される。

ちなみに、インタフェースの追加時にはens[192,225]のように入力すれば複数インタフェースをまとめて作成できる。

IPアドレス作成 (IP Addressesから)
作成したIPアドレスの一覧はIPAM -> IP Addressesから確認できる。
また、この画面の+ Addから作成も可能。

複数まとめて作成
IPアドレスの画面から作成する場合は、Bulk Createのタブから複数アドレスをまとめて作成もできる。

DHCPのアドレスレンジ
アドレスレンジの対象を前述の複数アドレス登録を指定しつつ、StatusからActiveでなくDHCPを選ぶ。
「〇〇というPCやスマホは今このアドレスを使っている」というリース状態をNetBoxで管理するのは難しそうな気がする(DHCPサーバーのリース状況をNetBoxが監視できる?)けど、「少なくともこのアドレスはDHCPの管理下なのでstaticな設定で使っちゃダメ」というのは見てわかるようになる。

もしかするとDHCPサーバー側がNetBoxからリースするアドレスレンジを取得する、というのはできたりするかも?(詳しくチェックはしてないけど、netbox dnsmasqとかisc-dhcp-server netboxでググるとそれっぽい情報がヒットする)
Kubernetes + MetalLBで使用するLoadBalancer Service用のIPアドレスもこの辺で予約しておくと良さそう。
IPアドレス使用状況

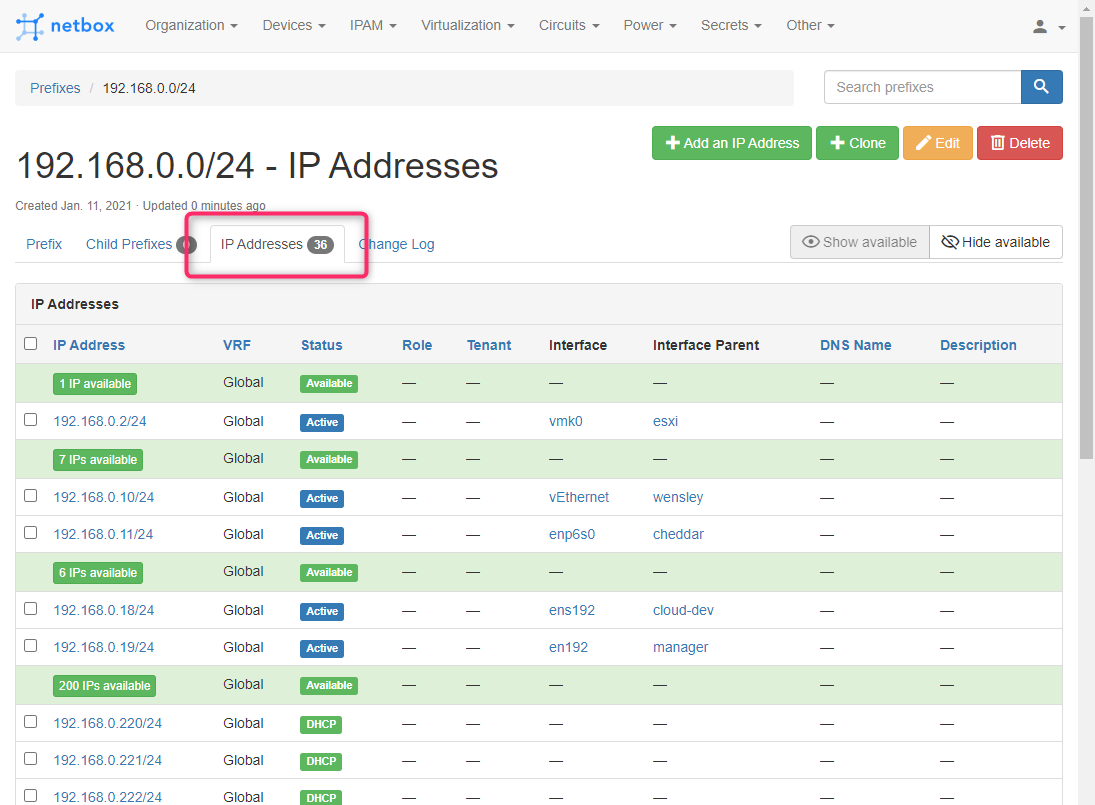
IPAM -> IP Addressesから作成済みIPアドレスの一覧は確認できるが、「誰が使ってるのか」「未定義(未作成)のIPアドレスがどれくらいあるのか」はパッとわからなかったり分かりづらい。
これはIPAM -> Prefixesを使うと俯瞰しやすい一覧を作れる。
+ AddでPrefixの作成画面から以下のように入力。
| 項目 | 値 |
|---|---|
| Prefix | 一覧対象にするネットワークアドレス(192.168.0.0/24など) |
| Status | Active |
| Is a pool | チェック無し |
| Site | 必要に応じて作成済みSite |
※ Is a poolはチェックすると、ネットワークアドレスとブロードキャストアドレスに相当するアドレス(上の例だと192.168.0.0と192.168.0.255)も"Available"扱いになるので扱いには注意。「ネットワーク全体」をNetBoxで管理する場合はチェックを外し、ネットワーク管理者は別に存在して「あなた(あなたのチーム)はこのアドレスを自由に使ってどうぞ」と言われて頭から尻尾まで全部ホストに割り当てられるアドレスを管理するのであればチェックすれば良いと思う。

作成すると192.168.0.0/24ネットワークの定義画面になり、この画面の「IP Addresses」を開くと、
が簡単に一覧から確認できる。 ネットワークマスクを調整し、サブネットワークアドレスについてもここで一覧にできる。
APIなど (リンク)
REST API使って参照や追加したり、Ansibleの入力(ダイナミックインベントリ)に使ったりもできるけど一旦ここまで。(→ ざっくり試してみた)
(画面キャプチャや説明文書きつつ手動操作してたというより先日のPC設定崩壊の復旧で力尽きた)
NetBoxを手動で使うとIPアドレス管理台帳.xlsxからツールが変わっただけ(で登録についてはむしろ手間がちょっと多い)だけど、NetBoxのAPIと連携することで、VM作成時に情報の登録を自動化に組み込んだり、メンテナンスや監視の対象ホストをNetBoxから動的に取得したりすることが可能になる、はず。つまり、管理の自動化と相性が良い。
Prefixの画面だけでもExcelの管理台帳から入れ替えできる情報量になっててよさそう。
まだまだ使い始めたばかりなので「NetBox使うのに〇〇機能を使わないのはおかしい」とか「その機能はそうじゃなくてこう使うんだよ」とか色々あるかもしれないけど、「とりあえず入れてみて手を動かしてみた」をやらないと前に進まないので試してみた記録。
ちなみに自宅で運用してたIPアドレス管理台帳(Googleスプレッドシート)はこんな感じ。(一部)
だいぶカオスってる。

1/28追記: 本文中にも書いているが、スペースを含んでいてもNetBox上には登録できるが、NetBoxにAPIアクセスするツール側で処理できない場合があるので、アンダーバーを使うなどした方が無難。
(教訓) NetBoxのフィルタ用(属性)各キーにスペースを含めるのはやめよう pic.twitter.com/h4YmcHIvHu
— z a k i (@zaki_hmkc) 2021年1月27日